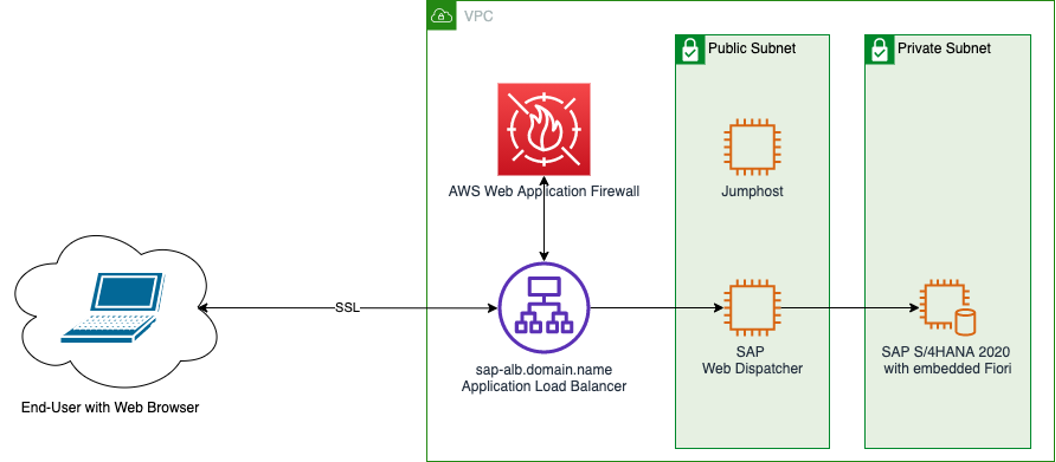
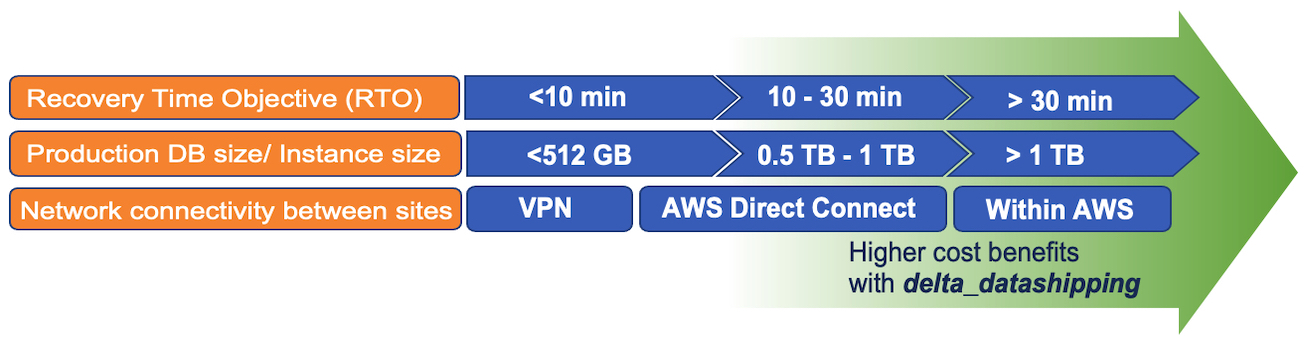
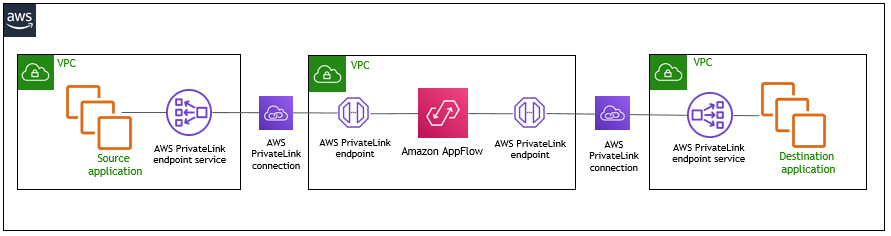
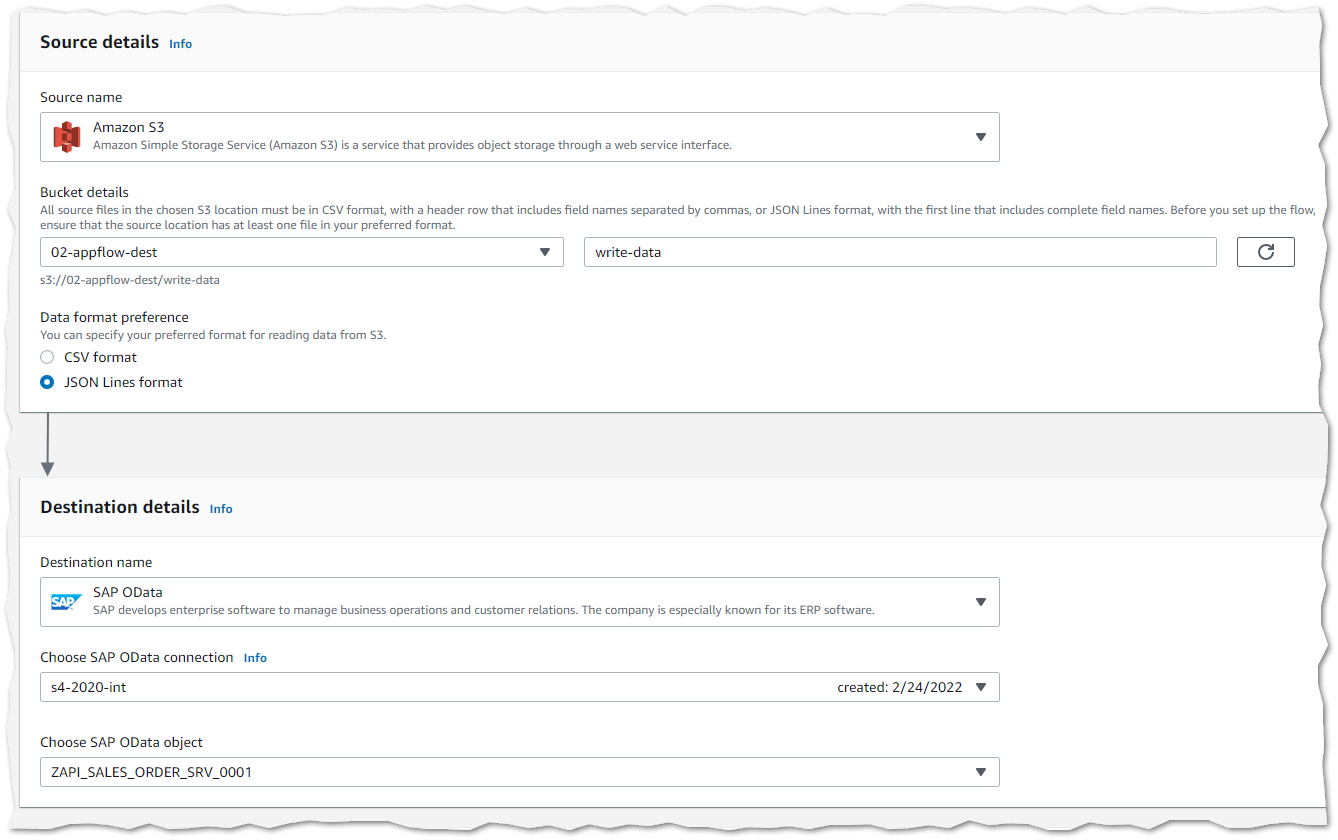
Feed: AWS for SAP.
Author: Axel Streichardt.
Introduction
Recently, SAP announced RISE with SAP, an offering that enables you to upgrade to SAP S/4HANA more easily through a single-tenant, SAP-managed ERP implementation. RISE with SAP further simplifies SAP S/4HANA adoption by bundling the technology needed to execute your cloud journey into a single offer with one contract. This offering delivers a standard production SLA of 99.7% (99.5% non-PROD) on the core RISE with SAP offering (and a 99.9% SLA with a price uplift), as well as a 20% reduction¹ in total cost of ownership (TCO) over five years compared to SAP S/4HANA on-premises deployments. AWS will be one of the cloud service provider (CSP) deployment options for RISE with SAP.

Our team will lean on its experience supporting SAP customers in order to help you reliably implement SAP S/4HANA through the RISE with SAP program. Our experience includes:
- 13+ years partnering with SAP and over 5,000 active SAP customers running on AWS, with more than half deploying SAP HANA-based solutions.
- Running 10 SAP Business Technology Platform (BTP, SAP’s Platform as a Service) regions globally).
- Offering best practices for migrating and managing SAP workloads on the cloud through our SAP-specific professional services practice – the only of its kind among CSPs.
- Analyst recognition, having been named as a “leader” for ten consecutive years in Gartner’s Cloud Infrastructure and Platform Services Magic Quadrant², as well as three consecutive years in the ISG Provider Lens Quadrant for SAP HANA Infrastructure Services³.
- Powering SAP’s future innovations and current product offerings, such as HEC, NS2, as well as some products exclusively on AWS, including SAP Concur, SAP Analytics Cloud, and SAP Data Warehouse Cloud.
- Providing end-to-end migration and transformation solutions for our customers with over 150 SAP technology, ISV, and GSI partners, as well as AWS’s ProServe team.
In wake of this announcement, many SAP customers are naturally reflecting on their own cloud journeys. RISE with SAP might represent the next step for customers who are ready for an S/4HANA transformation and looking for a fully managed offering that maximizes simplicity over customization. RISE with SAP users will give up the ability to leverage AWS services natively, but still be able to extend and innovate through specific partner add-ons and the SAP Business Technology Platform—which AWS supports in 10 regions—significantly more than any other cloud service provider. Some customers may find that these capabilities meet their needs for innovation, while others may want maximum flexibility to extend their systems to AWS services natively.
When we talk to our SAP customers, we find that each one has a different set of business priorities and challenges associated with their SAP systems. Some are drawn to offerings like RISE, to optimize for simplicity, while others want to retain the maximum flexibility to extend through AWS services that comes with using a traditional license on AWS.
A common theme that a lot of customers tell us is that they have plans to upgrade to S/4HANA at some point down the line, but don’t want to wait until they are on S/4HANA to get the cost, agility, or innovation benefits for their SAP workloads.
SAP modernization is not a “one size fits all” endeavor, which is why we opt to give our customers choice and flexibility on their SAP cloud journeys. I want to take this opportunity to detail a few different paths your business can take as it considers SAP migration. As you’ll see, these paths complement one another, and you have the option to shift to a different SAP strategy as your needs change. Let’s start with a lift-and-shift of SAP ECC.
Lift-and-shift
Lifting-and-shifting your existing ERP is often the best first step towards modernizing your SAP systems. That’s because lift-and-shift migrations allow you to move your SAP landscape to the cloud without altering the application or database layers, enabling an accelerated path to the cloud. Once you’re running on the cloud, you can start consolidating your SAP landscape and right-sizing resources to reduce costs, eliminate complexity, and add innovative solutions. From there, you have the option to pursue any number of activities, whether that entails maximizing the value of your existing SAP investments or upgrading to SAP S/4HANA.
One customer who has taken this route to ERP modernization is NBCUniversal. After lifting-and-shifting their SAP ECC systems to the cloud, NBCUniversal was able to remove customizations and redundancies from their SAP landscape, and project that they will reduce their TCO – by 23% over a 10 year period—a number they expect will improve as they continue to optimize their architecture and SAP Basis operations. In the long-term, these efforts will enable them to innovate on a clean core, without being inhibited by excessive modifications.
Innovating with SAP beyond infrastructure
Once you have migrated your SAP systems to the cloud and optimized infrastructure, you can begin modernizing core business systems through the adoption of advanced cloud services. On-premises, integrating emerging technologies into your SAP landscape can bring about significant cost, complexity, and risk. Pursuing these activities on AWS is more straightforward because we offer the broadest and deepest collection of cloud services among cloud providers with over 200 offerings. Furthermore, we continue to update these services, with over 90% of new features and services being launched in direct response to customer feedback. Commonly, SAP customers will look to services that enable the use of the Internet of Things (IoT), machine learning, and data lakes to drive greater operational efficiency, reshape business processes, improve customer interactions, and more.
Invista took this route to ERP modernization. Like NBCUniversal, Invista lifted-and-shifted their SAP systems to the cloud. From there, they progressed their cloud journey by innovating around their core business systems. Specifically, Invista migrated disparate data sources to AWS via AWS Snowball, bridging silos and enabling the use of advanced analytics to optimize inventory levels. They also leveraged Amazon Rekognition to improve quality inspections, dramatically reducing defect rates.
Refactor to SAP HANA
Another option is to refactor from an existing database (e.g., Oracle, IBM Db2, Microsoft SQL Server) to SAP HANA. In doing so, you unlock the in-memory data capabilities of SAP HANA, without committing to a complete SAP S/4HANA transformation. However, should you determine that SAP S/4HANA is right for your business in the future, refactoring to SAP HANA now eliminates the need to do so downstream.
One customer that opted to refactor to SAP HANA is Newmont. As part of their acquisition of Goldcorp, Newmont unified the two companies’ SAP ECC footprints. In doing so, they moved from an Oracle database to SAP HANA, taking an incremental step towards SAP S/4HANA adoption that will simplify a future upgrade to the next-generation ERP.
SAP S/4HANA transformation
If your business is ready to upgrade to SAP S/4HANA, you can rely on the experience and SAP-certified infrastructure of AWS. Since 2008, AWS has been collaborating with SAP to develop infrastructure purpose-built to meet the needs of even the most demanding SAP workloads. As a result of this work, AWS launched Amazon EC2 X1 instances in 2016 – the first cloud-native instances certified to support SAP S/4HANA – and High Memory instances in 2019. Leveraging Amazon EC2 High Memory instances, you can run SAP S/4HANA (OLTP) with up to 48TB of memory.
RISE with SAP on AWS gives you the opportunity to realize these performance capabilities in a streamlined manner, offering:
- A full scope SAP S/4HANA implementation, including line-of-business processes supporting 25 industries.
- Code enhancements and modifications to help you preserve customizations you’ve made to your SAP ECC landscape.
- Expert configurations to help you take full advantage of AWS infrastructure and services.
- The ability to extend and innovate through 10 SAP Business Technology Platform Regions.
Compared to other SAP S/4HANA deployment options, RISE with SAP provides simpler management, at the expense of the ability to use AWS service natively. This program offers support for brownfield, bluefield, and greenfield SAP S/4HANA deployments. As a result, you can more quickly convert your existing ERP implementation, or start fresh with a resilient and scalable cloud-based SAP S/4HANA architecture. At the same time, RISE with SAP allows you to transition from CapEx to OpEx via a single subscription. Overall, this program complements our existing options for running ECC and S/4HANA on AWS using traditional licensing models, making SAP S/4HANA available to a broader portion of the existing SAP customer base.
Determining the best path for your ERP modernization
RISE with SAP is one of many options that SAP customers have to modernize their ERP environments. Regardless of whether you’re ready for the full SAP S/4HANA transformation, it’s critical that you start taking incremental steps towards modernization. Doing so will help you wipe out antiquated processes, reduce costs, and start driving innovation around your core business systems. No matter which SAP strategy is right for your business, AWS provides tools, resources, and partner support to help you execute your cloud strategy.
If you’d like to learn more about RISE with SAP on AWS, visit our webpage today.
¹ https://www.sap.com/products/rise.html
² https://pages.awscloud.com/GLOBAL-multi-DL-gartner-mq-cips-2020-learn.html
³ https://pages.awscloud.com/GLOBAL-partner-DL-ent-sap-nov-2020-reg-event.html