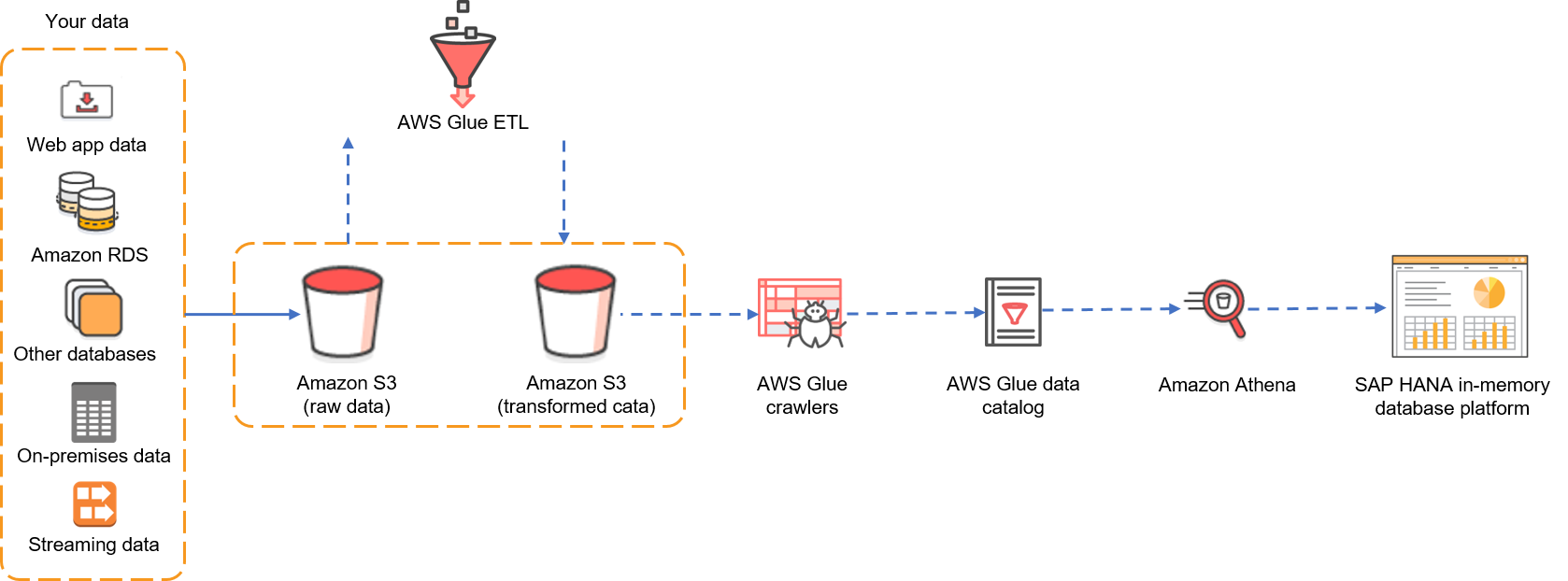
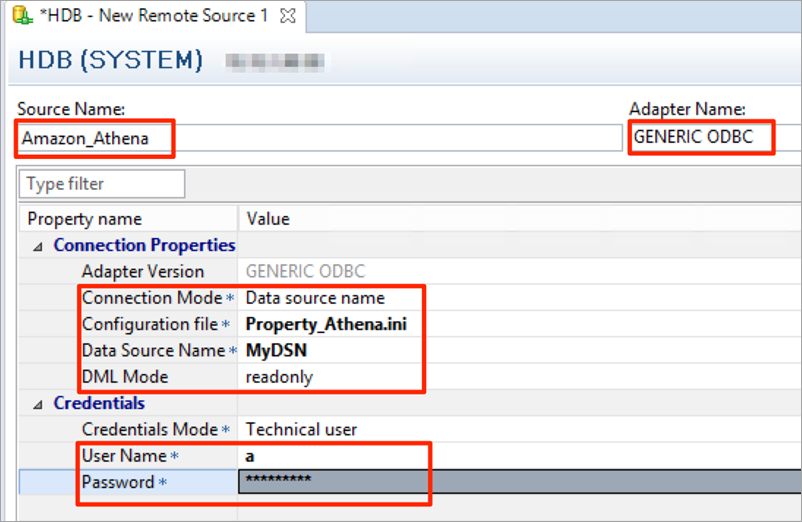
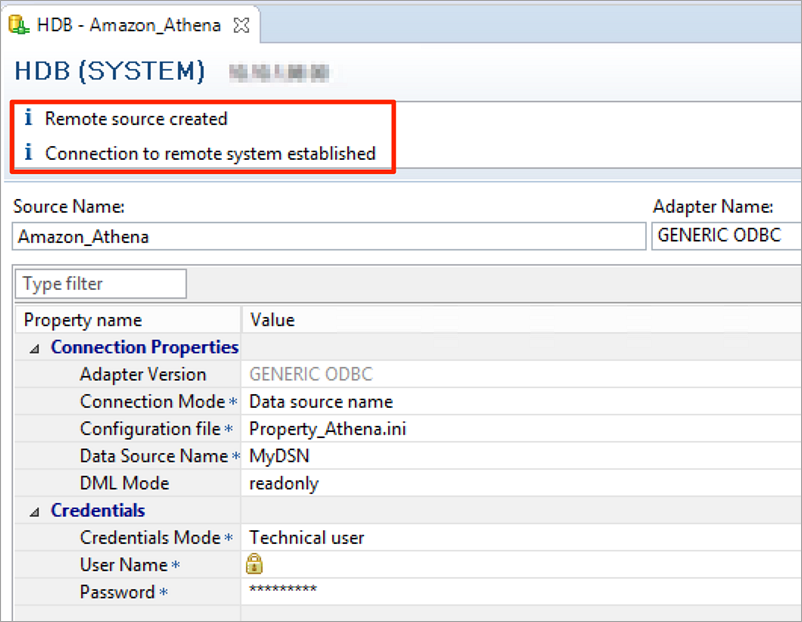
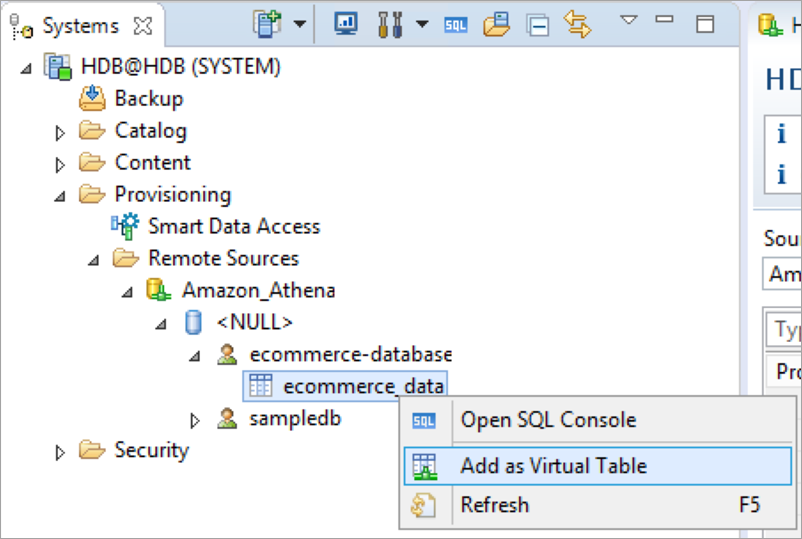
Feed: AWS for SAP.
Author: Somckit Khemmanivanh.
This post is by Harpreet Singh and Derek Ewell, Solutions Architects at Amazon Web Services (AWS).
SAP landscapes that need to reside within the corporate firewall are comparatively easy to architect, but that’s not the case for SAP applications that need to be accessed both internally and externally. In these scenarios, there is often confusion regarding which components are required and where they should be placed.
In this series of blog posts, we’ll introduce Amazon Virtual Private Cloud (Amazon VPC) subnet zoning patterns for SAP applications, and demonstrate their use through examples. We’ll show you several architectural design patterns based on access routes, and then follow up with detailed diagrams based on potential customer scenarios, along with configuration details for security groups, route tables, and network access control lists (ACLs).
To correctly identify the subnet an application should be placed in, you’ll want to understand how the application will be accessed. Let’s look at some possible ways in which SAP applications can be accessed:
- Internal-only access: These applications are accessed only internally. They aren’t allowed to be accessed externally under any circumstances, except by SAP support teams. In this case, the user or application needs to be within the corporate network, either connected directly or through a virtual private network (VPN). SAP Enterprise Resource Planning (ERP), SAP S/4HANA, SAP Business Warehouse (BW), and SAP BW/4HANA are examples of applications for which most organizations require internal-only access.
- Internal and controlled external access: These applications are accessed internally, but limited access is also provided to known external parties. For example, SAP Process Integration (PI) or SAP Process Orchestration (PO) can be used from internal interfaces, but known external parties might be also allowed to interface with the software from whitelisted IPs. Additionally, integration with external software as a service (SaaS) solutions, such as SAP SuccessFactors, SAP Cloud Platform, and SAP Ariba, may be desirable, to add functionality to SAP solutions running on AWS.
- Internal and uncontrolled external access: Applications like SAP hybris or an external-facing SAP Enterprise Portal fall into this category. These applications are mostly accessible publicly, but they have components that are meant for internal access, such as components for administration, configuration, and integration with other internal applications.
- External-only access: This is a rare scenario, because an application will need to be accessible internally for basic administration tasks such as backups, access management, and interfaces, even if most of its components are externally accessible. Due to the infrequency of this scenario, we won’t cover it in this series of blog posts.
In this blog post, we’ll cover possible architecture patterns for the first category of applications (applications that are accessible only internally). We’ll cover the two other scenarios in upcoming blog posts. In our discussions for all three scenarios, we’ll assume that you will access the Internet from your AWS-based resources, via a network address translation (NAT) device (for IPv4), an egress-only Internet gateway (for IPv6), or similar means, to deal with patching, updates, and other related scenarios. This access will still be controlled in a way to limit or eliminate inbound (Internet to AWS Cloud) access requests.
Architectural design patterns for internal-only access
We’ll look at two design patterns for this category of SAP applications, based on where the database and app server are placed: in the same private subnet or in separate private subnets.
Database and app server in a single private subnet

This setup contains three subnets:
- Public subnet: An SAProuter, along with a NAT gateway or NAT instance, are placed in this subnet. Only the specified public IPs from SAP are allowed to connect to the SAProuter. See SAP Note 28976, Remote connection data sheet, for details. (SAP notes require SAP Support Portal access.)
- Management private subnet: Management tools like Microsoft System Center Configuration Manager (SCCM), and admin or jump hosts are placed in this subnet. Applications in this subnet aren’t accessed by end users directly, but are required for supporting end users. Applications in this subnet can access the Internet via NAT gateways or NAT instances placed in the public subnet.
- Apps & database private subnet: Applications and databases are placed in this subnet. SAP applications can be accessed by end users via SAPGUI or over HTTP/S via the SAP Web Dispatcher. End users aren’t allowed to access databases directly.
Database and app server in different private subnets

This setup includes four subnets. The public subnet and the management private subnet have the same functions as in previous scenario, but the third subnet (the apps & database private subnet) has been divided into two separate private subnets for applications and databases. The database private subnet is not accessible from the user environment.
You see that there isn’t much difference between these two approaches. However, the second approach protects the database better, by shielding the database subnet with separate route tables and network ACLs. This allows you to have better control and to manage the access to the database layer more effectively.
Putting our knowledge to use
Let’s put this in context by discussing an example implementation.
Example scenario
You need to deploy SAP S/4HANA, SAP Fiori, and SAP BW (ABAP and Java) on HANA. These applications should be accessible only from the corporate network. The applications will require integration with Active Directory (AD) or Active Directory Federation Services (ADFS) for single sign-on (SSO) based on Security Assertion Markup Language (SAML). SAP BW will have file-based integration with legacy applications as well, and will communicate with an SSH File Transfer Protocol (SFTP) server for this purpose. SAP should be able to access these systems for support. SAP Solution Manager is based on SAP ASE and will be used for central monitoring and change management of SAP applications. All applications are assumed to be on SUSE Linux Enterprise Server (SLES).
Solution on AWS
In this example, we are presuming only one EC2 instance per solution element. If workloads are scaled horizontally, or high availability is necessary, you may choose to include multiple, functionally similar, EC2 instances in the same security group. In this case, you’ll need to add a rule to your security groups. You will use an IPsec-based VPN for connectivity between your corporate network and the VPC. If Red Hat Enterprise Linux (RHEL) or Microsoft Windows Server are used, some configuration changes may be necessary in the security groups, route tables, and network ACLs. You can refer to the operating system product documentation, or other sources such as the Security Group Rules Reference in the Amazon Elastic Compute Cloud (EC2) documentation, for more information. Certain systems will remain on premises, such as the primary AD or ADFS servers, and the legacy SFTP server.
Here’s an architectural diagram of the solution:
The architecture diagram assumes the following example setup:
The following table shows the security group sample configurations. This represents a high-level view of the rules to be defined in the security groups. For exact port numbers or ranges, please refer to the SAP product documentation.
The flow of network traffic is managed by these sample route tables:
*AWS Data Provider requires access to AWS APIs for Amazon CloudWatch, Amazon S3, and Amazon EC2. Further details are available in the AWS Data Provider for SAP Installation and Operations Guide.
For an additional layer of security for our instances, we can use network ACLs, such as those shown in the following table. Network ACLs are fast and efficient, and provide another layer of control in addition to the security groups shown in the previous table. For additional security recommendations, see AWS Security Best Practices.
In certain cases (for example, for OS patches), you may need additional Internet access from EC2 instances; and route tables, network ACLs, and security groups will be adjusted to allow this access temporarily.
What’s next?
In this post, we have defined and demonstrated by example the subnet zoning pattern for applications that require internal-only access. Stay tuned for the next blog post in this series for a discussion of the other subnet zoning patterns we introduced in this post.
We would like to hear about your experiences in setting up VPCs for SAP applications on AWS. If you have any questions or suggestions about this blog post, feel free to contact us.
Next article in this series: VPC Subnet Zoning Patterns for SAP on AWS, Part 2: Network Zoning